
# Crie uma sequência de números de 1 a 10
seq(from = 1, to = 10) [1] 1 2 3 4 5 6 7 8 9 10O treinamento de pesquisadores é fundamental tanto para a qualidade da pesquisa empírica quanto para a promoção do desenvolvimento técnico e econômico de um país. Através de instrumentos de representação e análise inferencial, a Estatística proporciona maior entendimento de acontecimentos quando se tem uma grande quantidade de dados, variabilidade e incertezas (Estevam & Kalinke, 2013). Além disso, o ensino de Estatística tem cada vez mais visibilidade, dado que existe, atualmente, no mercado de trabalho, uma necessidade de profissionais que saibam atuar frente a essa grande quantidade de informações e que dominem técnicas de análise de dados, antecipando a tomadas de decisões inferidas através de dados amostrais (Vendramini & Brito, 2001).
Faz-se necessário ainda que, devido a essa visibilidade, haja um maior cuidado na aplicação técnica da interpretação de dados, tendo em vista a expectativa de se encontrar a verdade por meio desses instrumentos (Cordani, 2001). Desse modo, existe uma necessidade de ampliar as oportunidades de formação de profissionais capacitados para lidar com essa demanda.
A ampliação da capacidade de processamento de computadores pessoais viabilizou que análises estatísticas relativamente complexas pudessem ser realizadas por um número abrangente de pessoas. Nesse contexto, surgiram diversos programas que facilitaram a realização de tais análises. Contudo, os aplicativos mais utilizados e populares são pagos e têm código fechado, isto significa que o código-fonte desses aplicativos não são abertos ao público em geral, apenas os desenvolvedores ou a empresa que detém os direitos autorais do software possuem esse conhecimento. Assim, a aquisição de licenças, em muitos casos, tem um preço proibitivo.
Nesse sentido, a linguagem de programação R se popularizou como uma versátil e poderosa ferramenta de análise de dados estatísticos, na medida em que é gratuita e tem código aberto, isso revela que o software possui acesso para visualização, utilização e modificação de acordo com os termos de licença específicos, proporcionando transparência, assim como a colaboração dos usuários para melhor desenvolvê-lo. Além disso, há uma enorme quantidade de desenvolvedores criando inúmeros pacotes que ampliam as possibilidades de análise do R. Um pacote R é um conjunto de funções, dados, documentação e outros recursos que podem ser instalados e usados no R. Os pacotes são uma forma de organizar e compartilhar código e dados, além de poderem ser usados para estender a funcionalidade do R.
Ademais, a comunidade de usuários interage fortemente e fornece suporte mútuo, esclarecendo dúvidas, avaliando mensagens de erro e contribuindo para que se encontre o melhor caminho para a realização de análises, construção de gráficos, tabelas, dentre outros. Outrossim, o aplicativo R Studio provê uma interface gráfica amigável que facilita o uso do R. Usados em conjunto, R e R Studio viabilizam a realização desde análises simples até a construção de modelos estatísticos complexos.
Nesse contexto, é necessário pensarmos na facilidade com a qual a sociedade pós-moderna tem acesso às informações. Isso permite que a busca pelos conhecimentos acadêmicos e profissionais aconteça de diversas formas, que vão muito além das tradicionais. Por isso, é pertinente adotar ferramentas que auxiliem na aprendizagem da Estatística, como as Tecnologias de Informação e Comunicação (TIC). Elas podem ser um meio poderoso nessa tarefa, pois, utilizadas de maneira adequada, favorecem a compreensão de conceitos estatísticos e probabilísticos. As TIC proporcionam um fácil e ágil acesso à aplicação dos conteúdos apreendidos (Estevam & Kalinke, 2013).
Nessa conjuntura, é possível elencar como exemplo os MOOCs (Massive Open Online Courses), que se tratam de cursos disponibilizados na internet, de maneira gratuita e aberta, não sendo necessário o cumprimento de pré-requisitos para sua realização. Salienta-se a não exigência de qualquer limite de participantes, de modo a permitir um público abrangente (Dal Forno & Knoll, 2014).
Os métodos utilizados nos MOOCs costumam ser fluídos. Nesse sentido, a grande maioria promove interação e visa a uma educação em parceria. Em contrapartida a isso, outros têm um teor tradicional, em que o professor, além de ser a principal fonte do conhecimento, dita as etapas pelas quais os alunos irão seguir (Cid Bastos & Biagiotti, 2014).
Os MOOCs foram introduzidos como modelos de educação à distância em 2008, porém, apenas em 2012, conseguiram tomar força através de investimentos, ganhando escala e popularidade, trazendo contribuições mundiais ao ensino superior (Gonçalves & Gonçalves, 2014). Desse modo, é possível considerar que os MOOCs têm pelo menos 10 anos de contribuição para a educação, com uma gama de cursos em diversas áreas e diversos níveis de conhecimento, técnicos e científicos.
Nesse cenário, podemos inferir que os MOOCs podem contribuir ricamente para a aprendizagem, visto que, além de serem acessíveis, são uma possibilidade de acontecer em paralelo a outras formas de ensino, como os cursos de Ensino Superior, pois concedem autonomia na gestão do tempo de conclusão. Além disso, por proporcionarem uma aprendizagem autodirigida, conferem aos estudantes a potencialidade de rever tópicos que requerem mais atenção, de acordo com suas necessidades. Os MOOCs são capazes, ainda, de viabilizar interação com os outros alunos do curso, o que pode proporcionar trocas de experiências e dicas, facilitando ainda mais o processo de aprendizagem.
Em 2023, a partir de buscas no Google, é possível encontrar alguns cursos brasileiros relacionados ao ensino do R. A plataforma de educação à distância Coursera disponibiliza diversos MOOCs, inclusive um específico de Análise de dados com programação em R, de nível Intermediário, oferecido pelo Google Career Certificates (Google, 2022). Outro exemplo foi encontrado na plataforma de MOOC do Instituto Federal do Espírito Santo (IFES), chamado Estatística com o R, que se direciona a alunos interessados em análise de dados por meio da aplicação de métodos estatísticos com essa ferramenta de pesquisa (Instituto Federal do Espírito Santo, 2024). Também foi encontrado no site de cursos da Escola Virtual do Governo, vinculada ao Governo Federal, um curso chamado Análise de dados em linguagem R, que possui como principal objetivo ensinar a utilização da linguagem R para a preparação e exploração de dados (Escola Nacional de Administração Pública, 2022).
No mais, também foram encontrados MOOCs em inglês sobre o ensino da linguagem R. A plataforma Coursera concede, além do curso supracitado em português, alguns outros cursos, como o “Introduction to R Programming for Data Science”, facilitado pela empresa International Business Machines Corporation - IBM - (IBM, 2024), e o “Data Science: Foundations using R”, disponibilizado pela Universidade Johns Hopkins(Johns Hopkins University, 2024).
Tendo isso em vista, é necessário apontar a importância de diferentes MOOCs sobre um mesmo assunto, isso porque, em relação aos cursos supracitados, há uma diferença entre os níveis de conhecimento e as habilidades trabalhadas. Por exemplo, o curso da plataforma Coursera tem nível intermediário, já aquele disponibilizado pelo governo é bem específico à sua forma de aplicação à Estatística, e, por último, o curso do IFES tem um conteúdo avançado em relação ao ensino de Estatística, porém só dá noções básicas sobre R. Ademais, os cursos ministrados em inglês podem dificultar o acesso de estudantes brasileiros que não dominem o idioma.
Ademais, os cursos possuem abordagens pedagógicas diferentes, que podem se adequar de maneiras distintas aos alunos, de forma positiva ou negativa, sobretudo quando os MOOCs atendem a um público abrangente, constituído de pessoas que possuem conhecimentos preestabelecidos e necessidades específicas. Logo, uma variedade de cursos potencializa o poder de escolha desses indivíduos sobre o quê e como preferem estudar.
Outro fator importante é que, no caso da linguagem R, por possuir código aberto, ela está em constantes modificações e evoluções. Isto pode tornar os cursos obsoletos, tornando necessária a atualização do conteúdo.
Este relatório apresenta o MOOC – “Introdução ao R para análise de dados em Psicologia”, que tem como objetivo ajudar pesquisadores e estudantes a fazer a transição de softwares proprietários e/ou com interfaces gráficas para uma linguagem de programação livre, gratuita e flexível.
A proposta ora apresentada se diferencia de outros cursos que ensinam R, no Brasil e em outros países, à medida que, apesar de sua excelência, o aprendizado é direcionado à Ciência de Dados ou à Estatística. Dessa forma, os conteúdos e a maneira como são apresentados têm uma complexidade que se afasta das tarefas mais rotineiras que são demandadas por pesquisadores da Psicologia ou das Ciências Humanas e Sociais de modo geral.
Não se tem a pretensão de esgotar as possibilidades que o R traz como linguagem de programação, mas adaptá-las às necessidades das áreas supramencionadas. Além disso, também se pretende fazer com que essa linguagem possa ser aprendida de forma intuitiva. A codificação a partir das funções básicas do R é muito poderosa e consegue implementar soluções avançadas, todavia parece não ter sido criada para se adaptar à linguagem cotidiana.
Nesse ponto, o uso de um conjunto de pacotes chamado tidyverse (Wickham et al., 2019) aproxima a codificação da linguagem natural, de modo que, além de ser lida por um computador, ela pode ser compreendida por um ser humano, o que é conhecido como programação letrada (literate programming). São verbos, advérbios, substantivos e pronomes que facilitam o entendimento sobre de onde se está partindo e para onde se quer chegar com as funções utilizadas. Aqui, há um pequeno revés: todas as funções estão em inglês, de maneira que um pequeno conhecimento sobre este idioma facilita o aprendizado. Assim, talvez esse MOOC fosse mais bem caracterizado como uma oficina sobre R através do tidyverse.
Além disso, a partir de uma formação inicial, gera-se também a possibilidade de utilização de cursos que requerem conhecimento prévio, como aqueles apresentados anteriormente. Por tudo isso, espera-se que os ingressantes do curso consigam desenvolver habilidades técnicas para a análise de dados em áreas das Ciências Humanas, através do manuseio do R. Para mais, pretende-se agregar conhecimentos críticos que sirvam de aporte para a interpretação de dados.
A formulação do curso seguiu as seguintes etapas: análise das necessidades (apresentada na introdução deste relatório), planejamento, implementação e execução (Fassbinder et al., 2014). Esclarecer estes pontos é fundamental para entender não só como o MOOC será conduzido e executado, mas também como se dá o processo pelo qual ele foi construído.
A fase de planejamento compreende a estruturação do MOOC. Assim, devem ser observados a forma que será utilizada para apresentar o conteúdo, a equipe responsável pelo desenvolvimento, a plataforma vinculada e os custos ou lucros da realização do curso. Seguindo essa lógica, quando se tratou da explanação do conteúdo, decidiu-se pelo formato de videoaulas gravadas e ministradas pelo Professor Dr. Francisco Pablo Huascar Aragão Pinheiro. Como se verá adiante, durante o período de elaboração deste relatório, o curso foi realizado no formato piloto com aulas ao vivo realizadas pelo Google Meet que foram gravadas. Dessa forma, a decisão sobre a plataforma através da qual o curso será disponibilizada ocorrerá posteriormente.
A equipe que desenvolveu o projeto é vinculada ao Laboratório de Práticas e Pesquisas em Psicologia e Educação (LAPPSIE) do campus Sobral da Universidade Federal do Ceará (UFC). Um grupo dentro deste laboratório tem se dedicado à produção de pesquisas quantitativas na área da Psicologia do Trabalho, como “Saúde discente em uma universidade pública: um estudo no nordeste brasileiro” (Vieira et al., 2022), “Prevalência e preditores de transtornos mentais comuns entre professores universitários do interior cearense” (Vieira et al., 2023) e “Características da violência contra professores de escolas públicas” (Pinheiro et al., 2020). O LAPPSIE compromete-se, ainda, com o ensino de técnicas de pesquisa quantitativa, em especial para o campo da Psicologia, tal como o curso ora apresentado.
A realização do MOOC não visa a lucros, de modo que ele será disponibilizado de maneira gratuita, na medida em que a UFC tem como missão disseminar conhecimento dentro e fora da universidade, visto que segue o princípio indissociável de ensino, pesquisa e extensão. Esses três pilares se conectam, portanto, com o objetivo de contribuir significativamente para a construção de uma sociedade livre, justa e solidária.
Durante a implementação, são avaliados o material didático no qual o curso será baseado, além da criação e do desenvolvimento de atividades. A oficina ora apresentada tem, até o momento, os livros “R for Data Science” (Wickham & Grolemund, 2023) e “Statistical inference via data science: A ModernDive into R and the tidyverse” (Ismay & Kim, 2022) como base. O primeiro é popular entre os cientistas de dados e também entre outras pessoas que querem aprender a utilizar a linguagem de programação R. Ele é conhecido por utilizar a abordagem “tidy data”, que permite a organização de dados de modo a facilitar a sua manipulação e a visualização. O segundo apresenta conceitos práticos e métodos computacionais, e também utiliza-se da linguagem R e do conjunto de pacotes do Tidyverse para análise de dados.
Foram desenvolvidos conjuntos de slides, blocos de exercícios e suas respectivas soluções, todos disponibilizados em uma página construída para, inicialmente, abrigar os conteúdos do curso https://fphap.quarto.pub/rpsi/. Estes materiais foram desenvolvidos a partir de codificação em R, através da ferramenta Quarto, uma linguagem de marcação que permite criar documentos dinâmicos, relatórios reprodutíveis, dentre outros. Ela pode funcionar, ainda, para a criação de materiais de ensino, como tutoriais interativos, exercícios, apresentações de slides e livros (como este que você está lendo).
Até o momento, foram desenvolvidos seis módulos para a oficina e um módulo sobre regressão está em construção. Em breve, serão acrescentadas discussões sobre estatística descritiva e sobre análises mais básicas: correlação, test t, ANOVA e qui-quadrado. A seguir, são apresentados os módulos já elaborados e uma amostra do que é aprendido em cada um deles.
Neste módulo, é apresentado o mínimo necessário para que seja possível familiarizar-se com a linguagem básica do R (R Core Team, 2022). Ao lidar com a codificação básica, nem sempre há uma transposição do que é feito em software com interface gráfica, mas este passo inicial é importante para que se entenda como R funciona por si mesmo.
Exemplo: função seq()
Os dois primeiros argumentos da função seq são: from e to
# Crie uma sequência de números de 1 a 10
seq(from = 1, to = 10) [1] 1 2 3 4 5 6 7 8 9 10Terceiro argumento: by
# Agora, o incremento da sequência é por 2
seq(from = 1, to = 10, by = 2)[1] 1 3 5 7 9Se os valores dos argumentos estiverem na ordem da função, é possível omití-los
seq(1,10,2)[1] 1 3 5 7 9Use a função rnorm e crie um objeto chamado cem com cem casos, cuja média seja 30 e o desvio padrão 4. Você pode ver os argumentos da função rnorm usando ?rnorm.1
Antes de analisar os dados colhidos, existem algumas tarefas que são essenciais no processo, como criar variáveis a partir daquelas coletadas inicialmente, filtrar valores e arranjá-los de forma ascendente ou descendente. Eventualmente, também é necessário selecionar variáveis, renomeá-las e mudá-las de posição. Sumariar alguns resultados é, ainda, uma atividade importante nessa fase de manipulação dos dados. Será visto que todas essas tarefas podem ser feitas com o pacote dplyr (Wickham, François, et al., 2023). Aprender como o dplyr funciona será o principal objetivo deste módulo.
O banco de dados ufo_sightings.csv vai ser empregado. Estes dados trazem informações sobre o avistamento de objetos voadores não identificados. Para obter os dados, execute o código a seguir:
ufo <- read_csv("./data/ufo_sightings.csv")Rows: 96429 Columns: 12
── Column specification ────────────────────────────────────────────────────────
Delimiter: ","
chr (7): city, state, country_code, shape, reported_duration, summary, day_...
dbl (1): duration_seconds
lgl (1): has_images
dttm (2): reported_date_time, reported_date_time_utc
date (1): posted_date
ℹ Use `spec()` to retrieve the full column specification for this data.
ℹ Specify the column types or set `show_col_types = FALSE` to quiet this message.Exercício
Os avistamentos ocorrem em diversos estados dos EUA. Qual o tempo médio de duração (em horas) do estado que mais tem avistamentos de objetos com o formato cigar?
ufo |>
mutate(
dur_horas = duration_seconds/3600
) |>
filter(country_code == "US",
shape == "cigar") |>
group_by(state) |>
summarise(
n = n(),
M = mean(dur_horas)
) |>
arrange(desc(n))# A tibble: 51 × 3
state n M
<chr> <int> <dbl>
1 CA 250 2.39
2 FL 146 1.74
3 TX 119 2.91
4 NY 109 2.63
5 WA 90 1.13
6 PA 88 2.95
7 OH 76 2.03
8 NC 72 2.42
9 IL 68 0.114
10 OR 68 0.0798
# ℹ 41 more rowsResposta: 2,39 horas
No contexto do tidyverse, iteração diz respeito a executar repetidamente a mesma ação em diferentes objetos. É possível, por exemplo, com a função summarise calcular a média e o desvio padrão de várias colunas de uma só vez ou transformá-las com a função mutate. A iteração é importante porque evita copiar e colar funções mais de duas vezes, o que pode gerar erros que se propagam pelo código. Essa é uma capacidade do tidyverse muito poderosa, contudo, dado o caráter introdutório da oficina, o foco será dado na função across().
Criação de um banco dummy
# A tibble: 10 × 4
a b c d
<dbl> <dbl> <dbl> <dbl>
1 -0.473 -0.192 0.806 -1.62
2 -0.271 -1.72 0.296 -0.367
3 1.03 -0.348 -0.681 -0.194
4 -0.491 -0.793 0.570 -0.0314
5 -0.502 -0.764 0.235 -0.963
6 1.07 -0.765 0.280 -0.456
7 -0.400 -0.0561 -1.55 -0.943
8 0.539 -1.04 -0.661 -0.460
9 -1.80 0.671 -1.71 -1.02
10 -0.00522 0.297 -0.198 -0.223 # A tibble: 1 × 4
a b c d
<dbl> <dbl> <dbl> <dbl>
1 -0.336 -0.556 0.0182 -0.458Exercício
No banco de dados economics calcule a média das variávels pce, pop e psavert usando a função across
economics |>
print(n = 3)# A tibble: 574 × 6
date pce pop psavert uempmed unemploy
<date> <dbl> <dbl> <dbl> <dbl> <dbl>
1 1967-07-01 507. 198712 12.6 4.5 2944
2 1967-08-01 510. 198911 12.6 4.7 2945
3 1967-09-01 516. 199113 11.9 4.6 2958
# ℹ 571 more rowsTrabalhar com os bancos de dados que acompanham o R e alguns pacotes é importante, mas este módulo permitirá que bancos de dados sejam levados para dentro do R. A importação é uma tarefa simples, mas que pode ter nuances que demandam atenção. Será aprendido a importar arquivos csv (valores separados por vírgula), csv2 (valores separados por ponto e vírgula), .sav (SPSS), .xlsx (Excel). Também serão abordadas algumas dicas sobre como organizar os dados e os nomes das variáveis e como exportá-los no formato csv. Para tanto, serão utilizados os pacotes readr (Wickham et al., 2024), haven (Wickham, Miller, et al., 2023) e readxl (Wickham & Bryan, 2023).
Lidando com códigos para valores ausentes
# A tibble: 6 × 5
`ID do Aluno` `Nome Completo` `Comida Favorita` `Plano de Refeição` Idade
<dbl> <chr> <chr> <chr> <chr>
1 1 Sunil Huffmann Iogurte de Morango Apenas Almoço 4
2 2 Barclay Lynn Batata Frita Apenas Almoço 5
3 3 Jayendra Lyne <NA> Café da Manhã e Almoço 7
4 4 Leon Rossini Anchovas Apenas Almoço NA
5 5 Chidiegwu Dunkel Pizza Café da Manhã e Almoço Cinco
6 6 Güvenç Attila Sorvete Apenas Almoço 6 Melhorando os nomes das variáveis
estudantes <- estudantes |>
clean_names()
estudantes# A tibble: 6 × 5
id_do_aluno nome_completo comida_favorita plano_de_refeicao idade
<dbl> <chr> <chr> <chr> <chr>
1 1 Sunil Huffmann Iogurte de Morango Apenas Almoço 4
2 2 Barclay Lynn Batata Frita Apenas Almoço 5
3 3 Jayendra Lyne <NA> Café da Manhã e Almoço 7
4 4 Leon Rossini Anchovas Apenas Almoço NA
5 5 Chidiegwu Dunkel Pizza Café da Manhã e Almoço Cinco
6 6 Güvenç Attila Sorvete Apenas Almoço 6 Gráficos são uma ferramenta muito importante para explorar os dados, assim como para tornar a apresentação de resultados mais inteligível, de modo que não seja necessário somente se ater à aridez das tabelas. Para tanto, é necessário trabalhar com uma ferramenta imprescindível: o pacote ggplot2 (Wickham, 2016). Neste módulo, serão apresentadas algumas funções para a criação de gráficos simples e, ainda, outras para o controle de vários elementos da figura que se quer produzir.
Duas variáveis numéricas
ggplot(penguins,
aes(flipper_length_mm,
body_mass_g)) +
geom_point() +
geom_smooth(
method = "lm"
)`geom_smooth()` using formula = 'y ~ x'Warning: Removed 2 rows containing non-finite outside the scale range
(`stat_smooth()`).Warning: Removed 2 rows containing missing values or values outside the scale range
(`geom_point()`).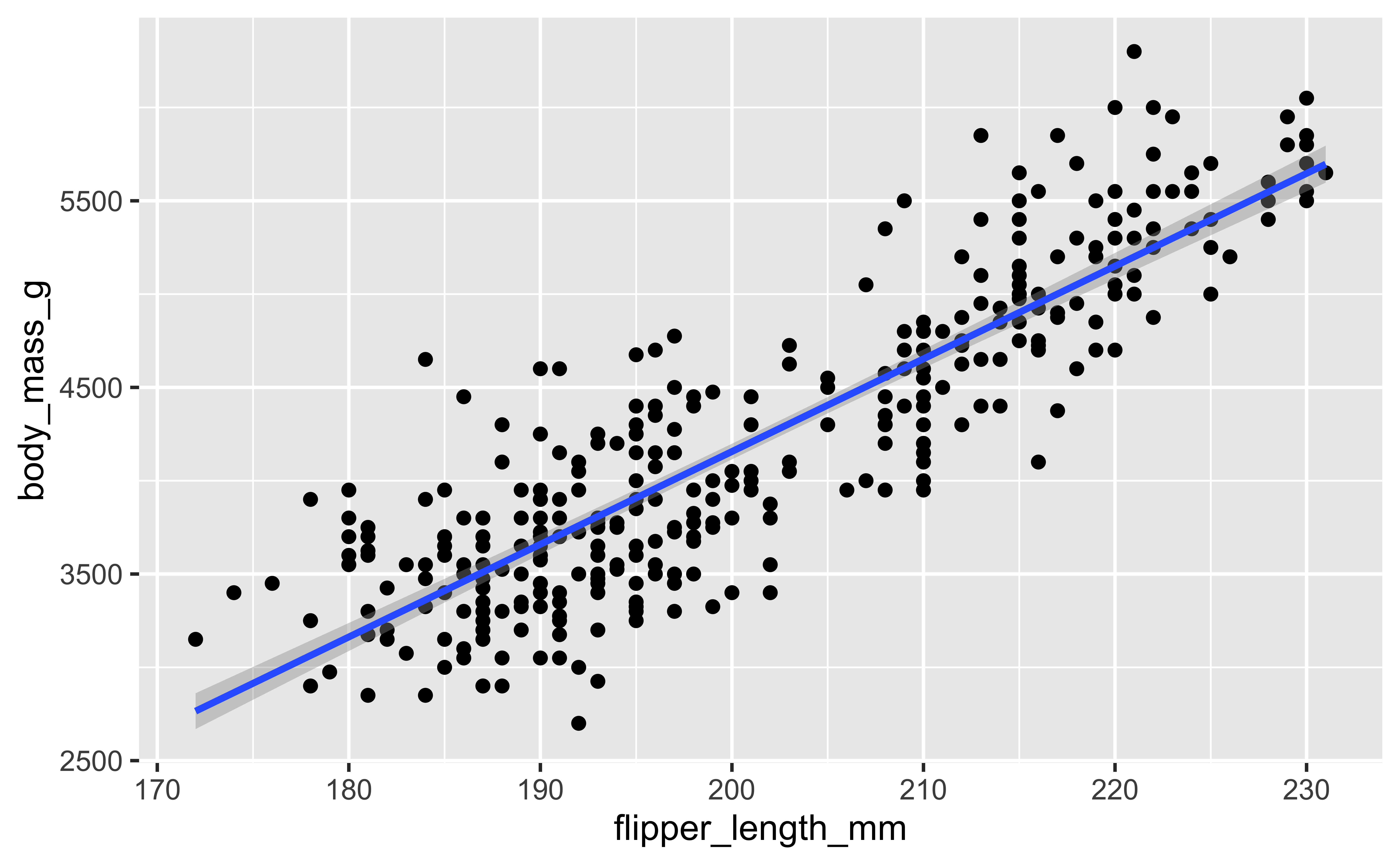
Exercício
Recrie o gráfico abaixo usando o banco de dados starwars.
Este talvez seja o módulo que mais se distancia do cotidiano de pesquisadores de Psicologia e de Ciências Humanas. Usualmente, trabalha-se com dados que são coletados, e, ao importá-los ou alimentar planilhas, já se obtém o formato tidy (arrumado). Este formato se refere ao seguinte: “Cada variável é uma coluna; cada coluna é uma variável. Cada observação é uma linha; cada linha é uma observação. Cada valor é uma célula; cada célula é um único valor” (Ismay & Kim, 2022).
Contudo, não é incomum o trabalho com, por exemplo, bancos de dados que sejam públicos ou que não tenham sido coletados diretamente, por isso é essencial conseguir meios de organização para que se possa executar as análises como dados arrumados (tidy data). Com este intuito, será explorada a função pivot_longer().
Regras para um banco de dados arrumado

“As três regras a seguir tornam um conjunto de dados organizado: variáveis são colunas, observações são linhas e valores são células” (Wickham & Grolemund, 2023, seçao 5.2, Tidy data).
Regressão linear é uma análise estatística simples, mas é uma ferramenta fundamental para a resolução de muitos problemas no cotidiano dos pesquisadores. Neste módulo, serão dadas noções básicas sobre esta ferramenta, bem como sobre a sua implementação no R. Além da função lm(), que está na base do R, serão utilizados alguns pacotes do tidymodels. O tidymodels é um conjunto de ferramentas e pacotes que fornece uma abordagem consistente e organizada para modelagem estatística e aprendizado de máquina, seguindo os princípios de organização e clareza do tidyverse. Ele facilita a construção, a avaliação e o ajuste de modelos estatísticos de forma eficiente e intuitiva.
Regressão Linear Simples: Uma Variável Independente Categórica
Rows: 1000 Columns: 98
── Column specification ────────────────────────────────────────────────────────
Delimiter: ","
chr (12): genero, cor_raca, escolaridade, estado_civil, renda_pos_pandemia, ...
dbl (86): a1, a2, a3, a4, a5, a6, a7, d1, d2, d3, d4, d5, d6, d7, e1, e2, e3...
ℹ Use `spec()` to retrieve the full column specification for this data.
ℹ Specify the column types or set `show_col_types = FALSE` to quiet this message.Diferenças Entre as Médias
t.test(tmcs ~ fct_relevel(grupo_de_risco, "Sim"), data = tmcs,var.equal = T)
Two Sample t-test
data: tmcs by fct_relevel(grupo_de_risco, "Sim")
t = 3.0395, df = 998, p-value = 0.002431
alternative hypothesis: true difference in means between group Sim and group Não is not equal to 0
95 percent confidence interval:
0.3887405 1.8051091
sample estimates:
mean in group Sim mean in group Não
5.630081 4.533156 fit_cat <- lm(tmcs ~ grupo_de_risco, data = tmcs) summary(fit_cat)
Call:
lm(formula = tmcs ~ grupo_de_risco, data = tmcs)
Residuals:
Min 1Q Median 3Q Max
-5.630 -4.533 -1.533 3.370 15.467
Coefficients:
Estimate Std. Error t value Pr(>|t|)
(Intercept) 4.5332 0.1790 25.33 < 2e-16 ***
grupo_de_riscoSim 1.0969 0.3609 3.04 0.00243 **
---
Signif. codes: 0 '***' 0.001 '**' 0.01 '*' 0.05 '.' 0.1 ' ' 1
Residual standard error: 4.915 on 998 degrees of freedom
Multiple R-squared: 0.009172, Adjusted R-squared: 0.00818
F-statistic: 9.239 on 1 and 998 DF, p-value: 0.002431Por último, é preciso delimitar como se dará a execução de fato do projeto, assim como a disponibilização do MOOC e o início do período de inscrições. Como mencionado anteriormente, o curso foi facilitado de maneira síncrona na plataforma do Google Meet e teve seus encontros gravados. Tratava-se de uma aplicação piloto que visava avaliar diversos pontos, com a intenção de aprimorar sua versão definitiva.
Por isso, foi dada atenção à qualidade dos slides, à forma de apresentação dos conteúdos, à interação com os exercícios e ao impacto das aulas no processo de aprendizagem dos mesmos. A participação e a avaliação dos discentes ao longo desse processo é imprescindível para a formulação do MOOC, na medida em que, em sua execução plena, não haverá contato direto com os alunos.
Nesta aplicação piloto, o facilitador utilizou slides para organizar a apresentação dos conteúdos e também fez codificações que acompanhavam as explicações. Os slides também contavam com exercícios que aplicavam as funções apresentadas. Desta forma, eram intercaladas as explicações com momentos para os discentes resolverem estes exercícios. Além disso, no site, existem blocos de exercícios correspondentes a cada módulo do curso, que eram resolvidos individualmente pelos participantes e, posteriormente, havia um encontro para que fosse feita a sua resolução em conjunto.
Tendo em vista que o MOOC está em processo de planejamento, ainda não há uma data específica estabelecida para o período de inscrições. Contudo, espera-se que ele esteja finalizado no ano de 2024.
Este trabalho dedicou-se a relatar o processo de desenvolvimento do curso “Introdução ao R para análise de dados em Psicologia”. A relevância do tema proposto foi apresentada, além das metodologias e estratégias adotadas na construção do MOOC. Adiante, será apresentada uma autoavaliação da proposta de MOOC, considerando-se os seguintes critérios: impacto; abrangência; abrangência potencial (possibilidade de expansão); replicabilidade; complexidade; demanda; inovação (avanço tecnológico).
No que diz respeito ao impacto, o curso se mostra relevante, na medida em que é uma porta de entrada para pesquisadores, da área de Psicologia e, de modo mais abrangente, da área de humanidades que precisam realizar análises estatísticas e podem fazer a transição de software proprietário para livre, com uma ferramenta robusta e confiável como R.
A utilidade do curso está em facilitar o aprendizado para pessoas que não tem familiaridade com linguagens de programação, ao direcionar os conteúdos às atividades costumeiras realizadas nas investigações das áreas supracitadas. Da mesma maneira, mostra-se relevante a abordagem de programação letrada, à medida que o aprendizado é facilitado quando se aproxima a linguagem natural da linguagem do software.
O curso terá abrangência internacional, pois ficará disponível na internet, o que permite o acesso ao público que tem familiaridade com a língua portuguesa. A abrangência potencial diz respeito à possibilidade de expansão e de atualização do curso. A primeira é possível através da criação de novos módulos que ampliem os conteúdos introdutórios, além da inclusão de outros que apresentem ferramentas avançadas do uso do R para análise de dados. Ademais, os módulos precisam ser periodicamente atualizados, porque os pacotes apresentados são aprimorados constantemente, o que pode torná-los obsoletos, caso não acompanhem esse desenvolvimento.
O curso terá um potencial de replicabilidade muito elevado, na medida em que todo o conteúdo produzido será lançado sobre uma licença CC BY-NC-SA 4.0 (Attribution-NonCommercial-ShareAlike 4.0 International), licença esta que “permite que outros remixem, adaptem e criem a partir do seu trabalho para fins não comerciais, desde que atribuam [ao autor] o devido crédito e que licenciem as novas criações sob termos idênticos” (Creative Commons, 2023).
Ademais, o código utilizado para a construção do curso foi disponibilizado publicamente no GitHub. Dessa forma, o próprio uso do R tornou o curso reprodutível e aberto, o que permitirá que outras pessoas possam revisá-lo e ampliá-lo.
O curso tem alta complexidade, porque a produção do MOOC exigiu formação adequada e esforços cognitivos, técnicos e sociais para sua realização. Isto se mostrou evidente nas diversas etapas necessárias para a construção do curso: seleção de literatura, produção de conteúdos e materiais, formulação de proposta didática que facilitasse o engajamento dos participantes e a aplicação do piloto, além do próprio conhecimento técnico sobre o R, que demandou tempo e recursos para sua aquisição.
Sobre a demanda, o curso atende a uma lacuna na formação de pesquisadores em Psicologia e Ciências Humanas. Como informado alhures, as propostas existentes que tratam do R como ferramenta para análise de dados são voltadas para as áreas de Estatística e Ciência de Dados, levando os conteúdos a um nível de complexidade que não atende à demanda das áreas visadas pelo MOOC.
Por fim, o MOOC é considerado de elevado padrão de inovação para a Psicologia, já que não existem outros cursos sobre a temática no Brasil especificamente direcionados às demandas da área e que, além disso, sejam gratuitos. Ademais, a replicabilidade por meio do uso de código aberto e de licenças tal qual a definida para a proposta não é comum no país.
Sempre que houver um bloco com “Run Code”, você pode usá-lo para digitar seu código e, em seguida, é só apetar o botão de play para executá-lo.↩︎